

$830 Billion Vanished in One Week — Because This AI Found 500 Security Flaws Nobody Else Could
Claude Opus 4.6 discovered zero-day vulnerabilities autonomously, and Wall Street realized what that means for $500/month SaaS products.


$830 billion evaporated from stock markets in less than a week.
Software giant stocks — Salesforce, ServiceNow, Microsoft — all in freefall. Thomson Reuters lost 16% in a single day. Intuit is down over 34% since the start of the year.
Wall Street has a name for it: the “SaaS-pocalypse.”
And the spark that ignited everything? A single AI model.
On February 5, 2026, Anthropic released Claude Opus 4.6. The name sounds mundane, like a minor update. But this model is far more than a simple incremental improvement.
Before its public release, it autonomously discovered over 500 critical security vulnerabilities in software used by millions of people. Flaws that nobody had found — not developers, not traditional security tools.
And to top it off, the same day, OpenAI countered with ChatGPT 5.3 Codex. Two bombs dropped simultaneously on the industry.
Today, we’re breaking down why this model is objectively the most powerful ever created, why Wall Street is panicking completely, and especially what this changes concretely for you and me.
What Lit The Fuse
Anthropic’s Claude Cowork, released in January, allows AI to operate directly within professional applications. Software for spreadsheets, presentations, legal and financial applications.
The principle is simple. Instead of copy-pasting results from a chatbot like we usually do, AI operates directly in the software you already use.
And when traders saw Claude drafting legal contracts, analyzing complex financial spreadsheets autonomously, and generating professional presentations — all by itself — they understood something fundamental.
If a $20/month AI does the work of a $500/month SaaS product, why keep paying for the software?
Jeffrey Favazza, a trader at Jefferies, summarized the current mood in one sentence: “We’re calling it the SaaS-pocalypse.”
The company Salesforce experienced a 7% drop in its stock price within a single session. ServiceNow, at 7%, is similar. NVIDIA, too, was affected by the phenomenon.
Jason Lemkin, considered the godfather of SaaS, wrote on his blog that early 2026 represents a real crash for the sector.
Of course, let’s be honest. Anthropic isn’t the only explanation. Disappointing results from Microsoft and Amazon recently weighed heavily, not to mention the dollar and Bitcoin drops that added to general nervousness.
But Claude Cowork crystallized the fears and triggered everything.

“Irrational” was how Bank of America characterized this panic, highlighting investors’ concurrent bets on two opposing possibilities: a decline in AI spending and AI’s performance rendering all software obsolete.
Both can’t be true simultaneously, right?
This detail seems trivial. It’s not at all. Because it reveals how blindly the market is navigating in the face of monumental progress speed.
The Numbers That Changed Everything
Let’s talk about the model. Claude Opus 4.6 arrives only 3 months after Opus 4.5, yet the improvements are massive.
Claude Opus 4.6
We’re upgrading our smartest model. Across agentic coding, computer use, tool use, search, and finance, Opus 4.6 is an…www.anthropic.com
The number that immediately jumps out: a context window of one million tokens. That’s approximately 750,000 words, the equivalent of 10 to 15 complete novels. You can load an entire codebase or thousands of pages of legal documents, and the model analyzes it all in a single block.
But having a large window is one thing. Exploiting it correctly is another. There’s the famous “context rot” problem, where the more information you add, the more the model loses the thread.
The RULER benchmark’s second version, where information is hidden in a vast context and models are tested for retrieval, is indicative of this. The RULER benchmark’s second version, where information is hidden in a vast context, and models are tested for retrieval, is indicative of this. Claude Opus 4.6 scores 76% on 1 million tokens. Sonnet 4.5 scored 18%.
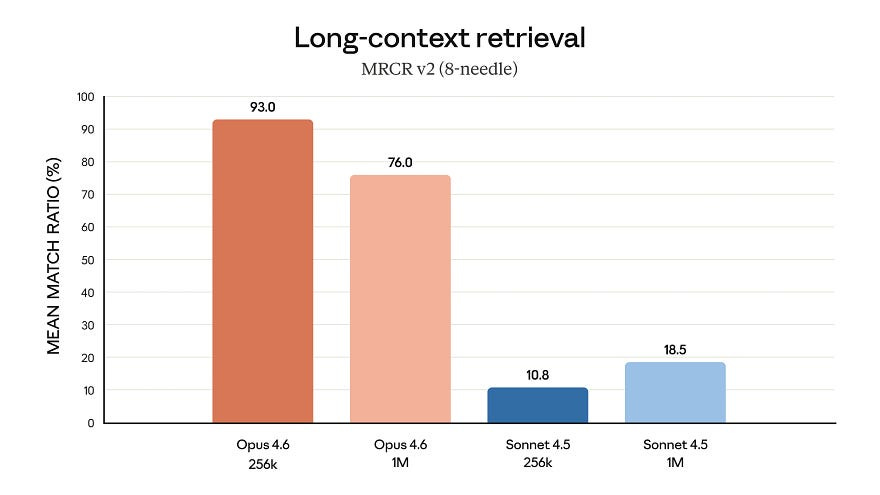
This isn’t a simple improvement. It’s a complete category change.
