
Every AI Model Is Built on a 10-Year-Old Flaw. Kimi just fixed it.
The team behind China’s Kimi model found a structural defect at the foundation of ChatGPT, Claude, Gemini, and every other AI you use.

I want to start with a question that might seem strange: what do ChatGPT, Gemini, Claude, Grok, Llama, and DeepSeek all have in common at the deepest level of their architecture? They all run on a design decision made in 2015, and nobody had seriously questioned it until now.
On March 16, 2026, the team behind Kimi, Moonshot AI’s large language model, published a paper titled “Attention Residuals” that identifies a structural flaw accounted for in the foundation of every modern AI model.
This is not a benchmark trick, a new dataset, or a bigger GPU cluster. Fundamental plumbing.
This thing we never touched because it has always worked well enough. Elon Musk reposted it. Andrej Karpathy, co-founder of OpenAI, commented that the paper “made us realize we hadn’t fully taken the title ‘Attention is All You Need’ seriously.” When researchers of that caliber react that way to a technical paper, it’s worth understanding exactly what was found.
The Infrastructure Nobody Questioned
You’ll need a general idea of how current AI models operate to get what Kimi’s team found.
A model like ChatGPT or Claude isn’t a single computation. It’s a stack of processing steps, called layers, piled one on top of the other — sometimes dozens, sometimes hundreds. When you send a message to any of these models, it passes through the first layer, which processes the raw words. The second layer starts to pick up on relationships between words. The third recognizes structure. By the tenth layer, the model grasps intent. By the fiftieth, it’s reasoning about meaning in abstract terms. Each layer adds depth. Each layer builds on what came before. The deeper the model, in theory, the more sophisticated its thinking.
The problem is that stacking layers creates a training problem. When a model makes a mistake, a correction signal needs to travel backward through the entire stack — from the deepest layer all the way back to the first — to update every layer’s behavior. But that signal weakens as it travels. Pass it through ten layers, and it’s still strong enough to be useful. Pass it through a hundred, and it arrives at the top so faint it can barely move anything. This phenomenon, known as the vanishing gradient problem, previously imposed a significant limitation on the depth of practical neural networks that could be constructed.
In 2015, Kai Ming He and his colleagues devised an ingenious solution. They implemented a shortcut that allows the original input to skip a layer and be directly combined with the output, rather than requiring each layer to transform the incoming data. Information doesn’t have to fight its way through every transformation — it can flow around them. This shortcut is called a residual connection, and it was so effective that it became the standard building block for every neural network built since. Every model you use today, without exception, relies on it.
What Nobody Noticed for a Decade
Residual connections solved the vanishing gradient problem well enough that nobody examined what else they might be doing. For eleven years, they were treated as a solved problem — a foundation you build on, not a foundation you revisit.
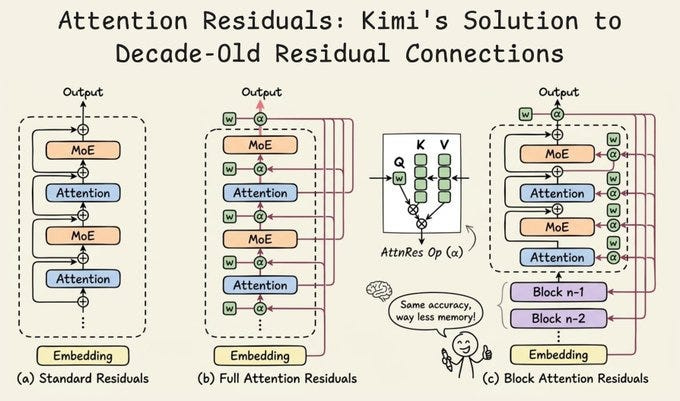
The Kimi team found the crack. Here is the specific problem: with standard residual connections, every layer receives the sum of all previous layers, and every previous layer contributes equally to that sum. The first layer counts as much as the fiftieth. The third counts as much as the ninety-ninth. There is no filtering, no selection, no judgment about which prior layer’s output is actually useful right now. It is blind accumulation — every layer adding its voice at equal volume to a growing pile.
This seems fine at first glance. But as a model grows deeper, that pile grows without bound. The hidden state — the accumulated representation that each layer receives as input — keeps growing as more layers contribute to it. And as it grows, each layer’s contribution becomes a smaller and smaller fraction of the total. Early layers, which capture basic information like vocabulary and syntax, get progressively buried. Their signal is still technically present, but it’s so diluted that the model can barely access it.
Meanwhile, the deepest layers face the opposite problem. To have any influence on the model’s final output, they need to produce signals large enough to stand out from the accumulated noise. The further down you go, the louder the subsequent layers must become, not due to increased significance, but merely to overcome the preceding noise.
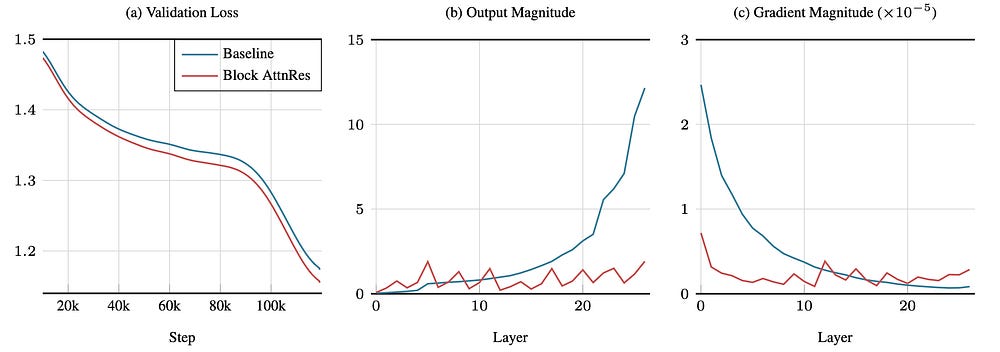
The paper demonstrates this directly: in standard models, output magnitudes grow monotonically with depth. The last layers produce disproportionately large signals, not because of what they’re computing, but because of an artifact of how the signals accumulate.
Think of it as an orchestra with no conductor. In the early rehearsals, when there are twelve musicians, you can hear every instrument. As you add players — fifty, a hundred, two hundred — the cellos from the opening section are still playing, but they’ve been overwhelmed by sheer volume. You can’t pick them out anymore. That’s exactly what happens in the deep layers of a transformer.
The Same Problem, Already Solved in a Different Dimension
This is where the Kimi team’s insight becomes elegant. They realized they had seen this problem before, just in a different context.
Before transformers existed, AI language models used recurrent neural networks — RNNs. These processed text one word at a time, maintaining a “memory state” that was updated at each step. The problem: as sentences got longer, information from earlier words got compressed into a single state vector that kept getting overwritten. By the time the model reached the end of a long sentence, it had effectively forgotten the beginning. This was called the amnesia problem, and it made early chatbots infamous for their inability to hold a conversation.

The transformer architecture, introduced in the landmark 2017 paper “Attention Is All You Need,” solved this by introducing the attention mechanism. Instead of compressing all previous words into a single blurred state, each word can look directly at any previous word and decide how much weight to give it. Retrieval is precise, adaptable, and relies on context, ensuring no data is lost through compression.
The Kimi team’s observation was precise: standard residual connections are doing to the depth dimension exactly what RNNs were doing to the sequence dimension. Each layer receives a single compressed state that blends everything that came before with equal weight, with no ability to go back and selectively retrieve a specific earlier representation.
Same structure.
Same problem. And therefore, potentially, the same solution.
