
Jensen Huang Called It a “Horrible Outcome.” Eight Days Later, DeepSeek Made It Real.
DeepSeek V4 Is the Largest Open-Source AI Model Ever Built. It Runs on Chinese Chips. And It Costs 1/7th of what you’re Paying Now.


You might remember what happened in January 2025. A Chinese startup that almost nobody outside the AI research community had heard of published a model that crashed Wall Street in hours. Hundreds of billions of dollars in market value evaporated because a team in Hangzhou had proved you could build a frontier AI model without spending billions. DeepSeek R1 matched the best from OpenAI, Anthropic, and Google at a reported training cost of $5.6 million. Andrej Karpathy, co-founder of OpenAI, called it a joke.
Not the model.
The budget.
The markets recovered. Investors exhaled. The consensus was that it was a one-off: DeepSeek got lucky; it would not happen again.
On April 24, 2026, it happened again.
What Actually Shipped
DeepSeek V4 has two models. V4 Pro has 1.6 trillion total parameters with 49 billion active per query, making it a Mixture-of-Experts architecture. V4 Flash carries 284 billion total parameters with 13 billion active. A context window of one million tokens, equating to about 750,000 words, is supported by both. This capacity is sufficient to ingest the complete Lord of the Rings trilogy and the first Harry Potter novel with ample room to spare.
Both are open source under the MIT license, downloadable for free on Hugging Face. V4 Pro has become the world’s biggest open-source AI model, surpassing Qwen’s Qimik 2.6 and more than doubling the size of DeepSeek’s V3, which was released in December 2024. And it launched exactly one day after OpenAI released ChatGPT 5.5. That timing was not accidental.
It was a signal.
The Real Innovation Is Not Size. It’s Cost.
Every week in AI, someone publishes new parameter counts and benchmark scores. What makes DeepSeek V4 genuinely different is not what the numbers are, but how the team got there — because DeepSeek did not have the resources to do it the way everyone else does.
The fundamental problem with large AI models today is not building them. It is running them once they exist. Three obstacles stand in the way. The first is the KV cache: as a model retains more context, its working memory grows, and the computation required grows with it.
Theoretically, a context window of one million tokens could be achieved, but its implementation is avoided because the cost of the necessary infrastructure is too high.
The second is training: months of continuous computation on thousands of GPUs, energy consumption comparable to a small city. For Chinese labs, this problem is compounded by American export restrictions that deny them access to the best Nvidia chips. Every available GPU has strategic value. The third is that the first two problems compound: the attention mechanism in a transformer follows quadratic scaling. Double the input text, and the computation required multiplies by four. It is a wall.
The American strategy for dealing with this wall has been to throw more hardware at it. More GPUs, more data centers, more billions spent. DeepSeek could not do that. They did not have the chips, and they did not have the budgets. So instead of hitting the wall harder, they found a way through it.
How They Broke Through the Wall
DeepSeek’s core architectural innovation in V4 is what they call hybrid attention: CSA (Compressed Sparse Attention) combined with HCA (Heavily Compressed Attention). Instead of treating every token in the context window identically, the model first compresses its working memory by grouping tokens, then selectively retrieves only the most relevant segments for each query. The CSA layer compresses the KV cache by a factor of four.
The HCA layer pushes compression much further, applying full attention to a version of the context so condensed that it remains computationally fast.
By alternating these two layer types throughout the transformer, the model achieves both fine-grained reading, where precision matters, and a broad overview of the complete context elsewhere. The results, as confirmed in DeepSeek’s technical report, are striking. When operating within a one-million token context, V4 Pro’s compute usage is 27% of what V3.2 required for identical tasks. The KV cache drops to 10% of its previous size. That means with the same GPU, you can handle ten times more context than before.
That is what makes the million token window actually usable in production, not just a marketing number.
But perhaps the most conceptually interesting innovation is what the technical report describes as conditional memory. In a standard transformer, the same attention mechanism handles two different jobs:
Retrieving factual knowledge and performing complex reasoning. It is like asking one person to manage your company’s archives and simultaneously solve your strategic problems. They can do both, but not as well as if they could focus on one at a time.
DeepSeek’s solution separates these functions. Static knowledge gets offloaded to a dedicated channel with constant-time retrieval — whether the knowledge base has a thousand entries or a hundred million, lookup time stays identical. This is an implementation of what researchers have been discussing for months under the name “computational forgetting,” a mechanism inspired by biological human memory. The idea is to let AI gradually compress older context to a lower resolution, consuming fewer tokens while retaining essential information.
Until now, it existed only in research papers. DeepSeek shipped it into production.
Where V4 Stands — Honestly
On performance, V4 Pro Max is the strongest open-source model in the world for reasoning and coding. On Codeforces, the competitive programming platform where experienced developers solve complex real-world problems, V4 achieves a rating of 3,206 — placing it roughly 23rd among human competitors. An open-source AI model ranks in the global top 25 against professional developers. It rivals ChatGPT 5.2 and Gemini 3.0 Pro across multiple standard benchmarks and approaches ChatGPT 5.4 on coding tasks. In formal mathematics, V4 Flash Max scored 81 on the Putnam benchmark, while Gemini 3 Pro scored 26.5. On the formal verification variant of Putnam 2025, V4 achieved a perfect 120 out of 120.
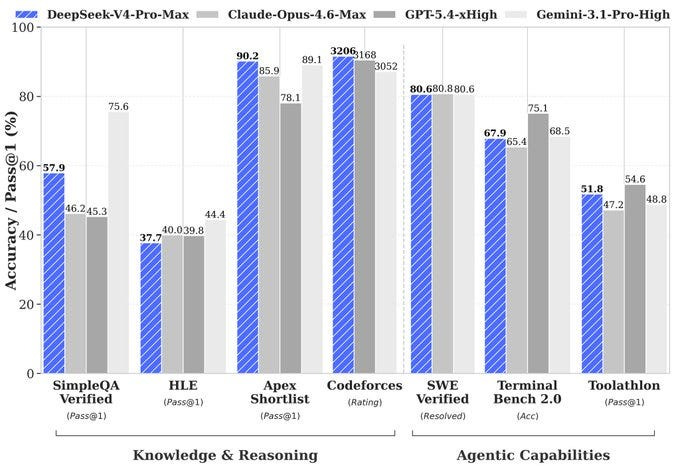
And to their considerable credit, DeepSeek is also honest about the limitations. In their own technical report, published alongside the model, they acknowledge a gap of approximately three to six months behind the best closed-source models like ChatGPT 5.5 and Gemini 3.1 Pro. Most companies show you only the benchmarks where they win. DeepSeek publishes the ones where they trail. That is rare enough in this industry to be worth noting.
V4 also handles only text.
No images, no videos, and no audio. On multimodal tasks, closed models like ChatGPT 5.5 and Gemini 3.1 Pro retain a clear lead. And the model is still in preview — DeepSeek has not announced a final release date. Incremental versions will ship progressively.
The Price That Changes Everything
V4 Flash costs $0.14 per million input tokens and $0.28 per million output tokens. V4 Pro has an input cost of around $1.74 and an output cost of about $3.48 per million tokens. For comparison:
ChatGPT 5.5, which shipped literally the day before, costs $5 input and $30 output. Claude Opus 4.7 is $15 input and $75 output. V4 Pro runs at roughly one-seventh the cost of the closest competitor for performance that is not far behind. V4 Flash is cheaper still by an order of magnitude.
And DeepSeek has already announced that V4 Pro pricing will drop further in the second half of 2026 when Huawei begins mass-producing its Ascend 950 compute nodes. For any company running AI in production at volume, this is not an advantage.
It is a big change.
Eight Days That Redrew the Map
This is where the story goes beyond technology.

Eight days before DeepSeek launched V4, Nvidia CEO Jensen Huang sat down with Dwarkesh Patel on the Dwarkesh Podcast and said something that, in retrospect, reads like a prophecy. His exact words:
“The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation.”
Eight days later, that is exactly what happened. DeepSeek gave early access to V4 exclusively to Chinese chipmakers. NVIDIA received nothing. AMD received nothing. On launch day, Huawei announced that its entire Ascend 950 Supernode line was compatible with DeepSeek V4 and that Huawei chips had been used for a portion of V4 Flash training. The software stack running it all is CANN, Huawei’s equivalent of CUDA.
That last point is the one that matters most. CUDA is the software ecosystem Nvidia spent two decades building into the foundation of virtually all AI development worldwide. Libraries, frameworks, training materials, tutorials — everything runs on CUDA. When a startup builds an AI product, it uses CUDA. When a government invests in AI infrastructure, they buy Nvidia because CUDA is where the software lives. NVIDIA’s real moat was never just the GPU hardware. It was the software ecosystem that locked everyone in.
What DeepSeek and Huawei are constructing is an entirely parallel stack: Chinese chips, Chinese software, Chinese models. All open source, all accessible to the rest of the world. A developer in Paris, a researcher in Geneva, a startup in Brussels — anyone can download V4 tomorrow morning and run it on non-American infrastructure.
Market reaction was immediate. SMIC, the foundry manufacturing Huawei’s chips, gained 9% in Hong Kong. Hua Hong Semiconductor surged 15%. On the other side, DeepSeek’s Chinese rivals took a beating: Zhipu AI and MiniMax both dropped 9%.
The Distillation Accusation
The timing of this launch collided with something else. V4 shipped one day after the White House accused China of stealing American AI intellectual property on an industrial scale. Michael Kratsios, who leads the White House Office of Science and Technology Policy, described campaigns of orchestrated distillation using thousands of proxy bot accounts.
In model distillation, you train a smaller model by having it copy the outputs of a larger one. OpenAI and Anthropic have both accused DeepSeek of doing exactly this with their models. China’s foreign ministry responded that the accusations were groundless and constituted defamation against the achievements of the Chinese industry.
That dispute is unresolved. What is not in dispute is that V4 became the fastest model in history to reach the top position on Hugging Face, as confirmed by Hugging Face ML engineer Lewis Tunstall.
Constraints Produced the Innovation
What this story demonstrates, and what makes it so uncomfortable for the American tech establishment, is that export restrictions on AI chips did not slow China down. They appear to have made Chinese AI more resourceful. Jensen Huang himself acknowledged this on the same podcast:
Even with inferior chips, China has the means to catch up with the United States thanks to its abundant energy and deep pool of AI researchers. Raw hardware power is one variable among several. Software optimization, team talent, and architectural ingenuity can compensate for a silicon disadvantage.
DeepSeek is the living proof. Denied the best Nvidia GPUs by American policy, their researchers were forced to find smarter solutions. Every external constraint produced a technical innovation. And because those innovations are published in open source, they benefit everyone. The gap between open-source and closed-source models narrows with every release. A year ago, open models were objectively a tier below. Today, they compete on the same field. And while performance converges, costs continue to collapse.
The philosophy underneath all of this is consistent across everything DeepSeek has built. You do not solve a problem by throwing more resources at it. You reformulate it until it becomes simple. Andrej Karpathy said it about DeepSeek’s OCR system. Jensen Huang dreads it about V4. Both are right.
The future of AI will not be determined solely by who has the biggest budget or the most data centers. It will also be determined by who finds the most elegant solutions to the right problems. And that, increasingly, is a competition where constraints are an advantage rather than a handicap.
Thanks for reading. Comment your thoughts. American export restrictions on AI chips did not slow China down. And because everything is open source, every developer on Earth benefits.