
Nvidia Dropped $20B on Christmas Eve and Admitted Their Chips Might Not Be the Future
Inside Groq’s 10x faster AI chips, the $255 billion inference market, and why the company that prints money just said they might have a problem


While you were unwrapping presents on December 24th, 2025, Jensen Huang was unwrapping something else entirely: a $20 billion check to acquire the one startup that kept him up at night.
And here’s the part that made me sit up in my chair: Nvidia just admitted something they’ve never said publicly before. Their chips might not be the best for AI’s future.
Let that sink in for a second. The most valuable company on the planet, the one that’s been printing money faster than any tech company in history, just looked in the mirror and said, “We might have a problem.”
I spent the last week going down the Groq rabbit hole (yes, with a Q), and what I found explains why this acquisition could change how we interact with ChatGPT, Claude, and every AI tool you use daily. More importantly, it reveals what’s coming for the job market in the next few years, and you probably won’t like it.
The Man Who Made Google Independent from Nvidia
Jonathan Ross isn’t some random startup founder who got lucky. This guy is literally the father of Google’s TPU chips, the ones that power Gemini and allowed Google to break free from Nvidia’s stranglehold. When you ask Gemini a question and get an instant response, that’s Jonathan’s engineering work you’re experiencing.
In 2017, Ross left Google with an insight that everyone thought was crazy at the time but turned out to be prophetic. He believed the AI industry would need specialized chips, not general-purpose ones like Nvidia’s GPUs.
Here’s where it gets really exciting, and this is the part most people miss.
Nvidia’s GPUs, those graphics cards that now cost more than a decent used car, were originally designed to render video games. They’re excellent at calculating millions of triangles in parallel to display realistic explosions in Call of Duty. By happy accident, this type of parallel processing also works great for training AI models.
But here’s the problem nobody talks about.
The Hammer Piledriver Problem
When you ask ChatGPT a question today, the model isn’t training. It’s doing what’s called inference, generating words one by one sequentially. And for this specific task, using a GPU is like using a sledgehammer to hang a picture frame. It works, sure, but it’s wildly inefficient. We’ve just been using them because we didn’t have anything better.
Groq built something radically different: the LPU (Language Processing Unit). And the numbers are absolutely stupid.

Where a high-end GPU generates around 100 tokens per second, Groq’s LPUs hit 300 tokens per second. When you chat with an AI hosted on Groq, responses arrive so fast you don’t even see the words appearing one by one. The entire text appears instantly, as if someone pasted it.
The secret? Memory architecture.
Nvidia’s GPUs use external HBM memory with a spare capacity around 8 terabytes per second. Groq’s LPUs utilize SRAM memory directly integrated into the chip, boasting a capacity of 80 terabytes per second. That’s 10 times faster.
This is the technical advantage that makes billion dollar companies sweat.
The $255 Billion Market Nobody’s Watching
The AI industry is experiencing a massive shift that most people completely miss because they’re staring at the wrong thing.
For years, everyone obsessed with training. OpenAI is spending $100 million to train GPT-4, and Google is mobilizing entire server farms to build Gemini. Training is glamorous; it makes headlines, VCs throw money at it.
Except that training is a one-time expense. You train a model once, and it’s over.
Inference is where the real money lives.
Every time you send a message to ChatGPT, every time a fraud detection system analyzes a transaction, every time an autonomous car makes a decision, that’s inference. And these costs accumulate with every single use.
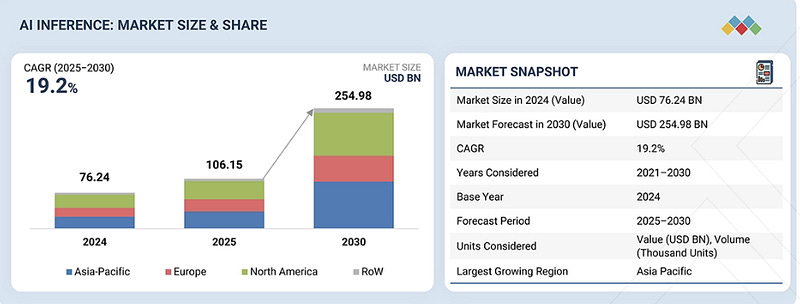
According to recent market analysis, inference represents 80 to 90% of total costs over an AI system’s lifetime. The inference market is projected to hit $255 billion by 2030, up from around $100 billion today.

Jensen Huang didn’t become one of the richest people on Earth by being naïve. He saw this transformation coming from miles away and realized Nvidia risked getting trapped in the training market while companies like Groq and Cerebras captured the inference goldmine.
It’s exactly what happened with Google and its TPUs. Google developed its own specialized chips, so they liberated themselves from Nvidia dependency, and now they’re selling those chips to other companies. Nvidia couldn’t let that story repeat.
The Licensing Loophole That Regulators Hate
What makes this acquisition even more fascinating is its structure, and this is where Silicon Valley gets creative with antitrust laws.

Officially, this isn’t an acquisition. It’s what Nvidia calls “a non-exclusive licensing agreement.” Nvidia gets all of Groq’s intellectual property and recruits Jonathan Ross, plus nearly the entire leadership team. But technically, Groq continues to exist as an independent company with a new CEO, Simon Edwards.
This legal gymnastics isn’t innocent.
Remember Windsurf last summer? OpenAI was about to acquire this coding AI startup for $3 billion, but Microsoft (which owns rights to OpenAI’s IP) blocked the deal. So what happened? Google swooped in, offered $2.4 billion to recruit the CEO and key engineers, license the technology, and leave the company existing as an empty shell. Three days later, Cognition (the company behind Devin AI) bought what remained of Windsurf for only $250 million.
Meta did the same thing with Scale AI: $15 billion for a 49% stake, recruiting founder Alexander Wang to run their AI efforts, while Scale “officially” continues as an independent company. They basically gutted them. The valuation crashed.
Silicon Valley found a workaround to antitrust regulators: don’t buy companies, buy their brains and technology. Leave the corporate shell behind like a cicada’s exoskeleton.
Why This Changes Everything (Including Your Job)
Nvidia now has $61 billion in cash and short-term investments. Twenty billion is pocket change for them. But with this acquisition, they got something far more valuable than money: the ability to dominate the inference market like they already dominate training.
In his email to employees, Jensen Huang was crystal clear. Nvidia plans to integrate Groq’s low-latency processors into its AI factory architecture. Concretely, this means Nvidia customers will soon be able to buy packages combining Nvidia’s Blackwell GPUs for training and Groq’s LPUs for inference. Best of both worlds.
But here’s the part that really matters, and it’s technical but crucial.
Nvidia owns CUDA, the software library that makes its chips absurdly easy for developers to use. It’s their true advantage over every other chip company. Now they’ll extend CUDA to work with Groq chips too. One software platform, two chip types, maximum simplicity for developers.

What impresses me most? Groq’s chips use 14-nanometer fabrication technology, which is over 10 years old. Nvidia uses 4 nanometers today. Despite using ancient technology, Groq was competing on inference performance. Now imagine giving Jonathan Ross access to the world’s most advanced fabrication plants, Nvidia’s R&D budget, and their entire software ecosystem.
The result could be absolutely revolutionary.
The New World Order (And Where You Fit In)
When inference becomes not two or three or four but 10 times cheaper and faster, entirely new use cases become possible. Voice assistants that respond instantly. AI agents that think and act in real time. AI applications are embedded in consumer devices without a permanent cloud connection.
Bank of America analysts nailed it:
“This acquisition implies Nvidia recognizes that while GPUs dominated AI training, the rapid shift toward inference may require more specialized chips.”
That’s a remarkable admission from the most valuable company on the planet.
For us as daily AI users, interactions are about to become even more fluid, faster, and more natural. The barrier between asking a question and receiving an answer will practically disappear. And this fluidity will accelerate AI adoption across every sector of the economy.
Which brings me to a question you’re probably asking yourself right now.
With chips generating responses faster than you can read, with inference costs literally collapsing, with AI agents becoming increasingly autonomous, how do you position yourself in this new world?
And I use that term intentionally: new world.
Are you someone who undergoes these transformations, or someone who knows how to use them to your advantage?
Here’s the reality I’ve been saying for a while now: these technologies won’t replace humans. They’ll amplify those who know how to use them. It’s already happening. Companies aren’t looking to replace employees with AI. They’re looking for employees who know how to use AI to be 10 times more productive.
The difference between these two types of people is simply their level of training.
The gap is widening fast. The people who learn to work with AI are pulling ahead at an exponential rate, while everyone else is arguing whether AI will take their jobs. By the time the debate settles, the answer will be irrelevant because the winners will have already moved on to the next thing.
Nvidia just bet $20 billion that inference is the future. They’re probably right. The question is: what are you betting on?
Please let me know your thoughts in the comments. I will be pleased to discuss this with you.