

The First Open-Source Model to Beat Claude on Agentic Tool Use Costs Five Times Less.
Kimi K2.7 Code, the Distillation Accusation, and Why the Harvard Professor Who Studied Disruption for 30 Years Would Recognize This Pattern Instantly


Here is what actually happened on June 12, 2026. Moonshot AI, a Beijing-based startup founded in 2023 by Zhilin Yang (a Tsinghua alumnus and former Google researcher who worked on the original Google Imagen model), released Kimi K2.7 Code on Hugging Face under a Modified MIT license. It is a coding-focused, agentic AI model with 1 trillion total parameters, 32 billion active per query, and a 256,000-token context window. It is free to download. That is open-source. And on one very specific and very important benchmark, it beat both Claude Opus 4.8 and GPT-5.5.
On MCP Mark Verified, which measures a model’s ability to correctly invoke tools through the Model Context Protocol (think CI pipelines, GitHub operations, database queries, Notion updates, file edits, all chained together in a single automated loop), Kimi K2.7 Code scored 81.1%. Claude Opus 4.8 scored 76.4%. GPT-5.5 scored 74%. An open-source model, five times cheaper to run, outperforms the two most powerful closed-source models in the world on the metric that matters most for autonomous AI agents.
That is a genuinely significant result. But it is also a narrower one than the excitement suggests, and understanding both the achievement and its limits is what separates useful analysis from hype.
What K2.7 Code Actually Does — and Doesn’t — Beat
Precision matters here because the framing around this release has been sloppy.
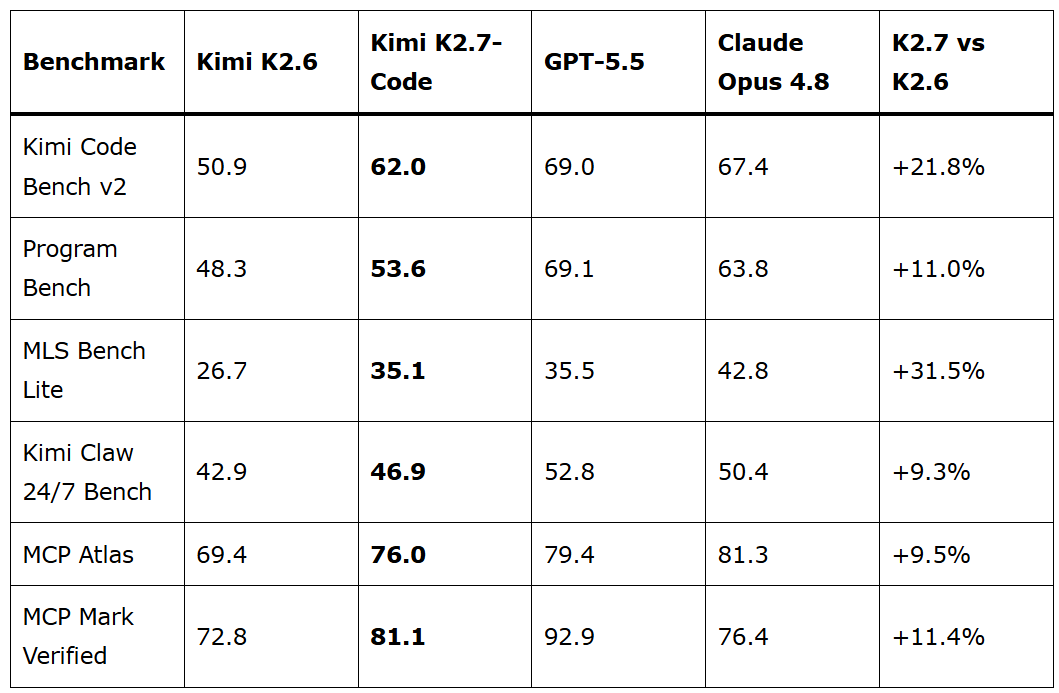
On Moonshot’s own published benchmark table, GPT-5.5 remains ahead of K2.7 Code on all six listed benchmarks. On Kimi Code Bench v2, GPT-5.5 scores 69.0 against K2.7’s 62.0. On Program Bench, GPT-5.5 scores 69.1 against K2.7’s 53.6. Claude Opus 4.8 also leads on most rows. The single exception is MCP Mark Verified, where K2.7 takes the top position.
Every benchmark published for K2.7 Code at launch is either a Moonshot proprietary benchmark or was run by Moonshot’s own team. As of June 25, 2026, no independent third-party results exist on SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, LiveCodeBench, or any other public leaderboard that runs all models under the same controlled conditions. The improvements over K2.6 (21.8% on Kimi Code Bench v2, 11% on Program Bench, 31.5% on MLS Bench Lite) are directionally meaningful but should be treated as vendor-reported until independently confirmed.
That said, the MCP Mark result is not a proprietary benchmark. It tests tool invocation across real environments: Notion, GitHub, filesystem operations, PostgreSQL, and Playwright browser automation. Beating both frontier closed models on that specific capability, while being open source and five times cheaper, is the result that matters for anyone building AI agents in production.
Why It Matters Even If You Don’t Write Code
There is a misconception worth addressing directly. A model specialized in coding is not a model only for programmers. In 2026, a model that writes code is a model that builds things for you: a website, a data visualization, an automation pipeline, a dashboard, an internal tool. You describe what you want. The model writes the code to make it exist. You never touch a line of syntax. Coding has become the language in which AI constructs solutions on your behalf. A model that is better at coding is a model that is better at making things you need.
K2.7 Code uses the same Mixture-of-Experts architecture that has defined the Kimi family since K2.5. One trillion total parameters, but only 32 billion active at any given moment. Think of it as a team of 384 specialists, of which only the eight most relevant are mobilized for each task. That gives the power of a giant model with the inference cost of a mid-sized one. The context window supports 256,000 tokens and accepts text, images, and video, so you can show the model a screenshot of a bug, and it works from the visual input directly.
The efficiency gain is where the practical impact lives. Moonshot reports a 30% reduction in reasoning tokens compared to K2.6. Reasoning tokens are billed as output tokens. For agentic workflows that run hundreds or thousands of steps, each step generating its own chain of thought, a 30% cut compounds across every run. That is not a benchmark number. That is a production cost reduction that shows up on the invoice.
The Distillation Question That Nobody Wants to Answer
The K2.7 Code’s powerful performance with tool use has a basis. And the timeline is uncomfortable.
In February 2026, Anthropic publicly accused Moonshot AI, alongside DeepSeek and MiniMax, of conducting industrial-scale distillation campaigns against Claude. The accusation was specific: 24,000 fraudulent accounts, 16 million total exchanges, of which 3.4 million were attributed to Moonshot alone.
According to Anthropic’s published report dated February 23, 2026, what Moonshot was specifically targeting was Claude’s agentic reasoning: its capacity for tool use, its coding ability, and its computer vision.
Exactly the domains where K2.7 Code now excels.
Moonshot has never responded publicly to the accusation.
Read the sequence in order. Moonshot targets Claude’s tool-use capability through fraudulent accounts. Four months later, Moonshot releases a model that beats Claude on tool use. The coincidence is, at a minimum, difficult to ignore.
Does this mean K2.7 is a “stolen” model? That is an overstatement. Across the industry, training a smaller model to copy the outputs of a larger model, known as model distillation, is a familiar and frequently employed method. American labs use it too. OpenAI, Google, and Anthropic themselves all employ distillation as part of their training pipelines. The controversy is not the technique. It is the scale, the use of fraudulent accounts, and the refusal to address the accusations.
The Geopolitical Context That Makes Everything Larger
This release did not happen in a vacuum. The U.S. government invoked national security to restrict access to Anthropic’s most advanced frontier models for foreign nationals. Anthropic had to disable its most powerful systems for users outside the United States. The market response was immediate: Zhipu AI, the Chinese lab listed in Hong Kong, surged 33% the day after the announcement. When America closes the door, China catches the developers who walk through the other one.

The numbers on Hugging Face confirm the structural shift. Chinese models now represent 41% of all platform downloads against 36.5% for the United States. Alibaba’s Qwen has surpassed Meta’s Llama with over 700 million cumulative downloads. Qwen derivatives now account for nearly half of all new model uploads on the platform. Llama has fallen to 12%. The center of gravity of open-source AI has moved continents.
Moonshot is riding this wave with extraordinary momentum. The startup was valued at $4.3 billion in December 2025. It closed a new round at $20 billion in May 2026 and is reportedly targeting $30 billion for its third financing round in six months, according to Bloomberg. Annual recurring revenue doubled from $100 million to $200 million in six weeks — a 7x multiplication in valuation in a single semester. Finding a precedent in the history of technology startups is genuinely difficult.
Alibaba Recently Launched a Model, a Chip, and a Shopping Agent. Europe Wasn’t Watching.

On May 14, a model that no one had ever seen before quietly appeared on Arena AI, the crowd-sourced leaderboard where developers run blind head-to-head comparisons between the best AI systems in the world. No press release.
The Pricing That Rewrites the Economics
K2.7 Code costs $0.95 per million input tokens and $4.00 per million output tokens through Moonshot’s API. Claude Opus 4.8 runs at approximately $15 input and $75 output. GPT-5.5 is a $5 input and a $30 output. K2.7 is roughly five times cheaper than the closest competitor for performance that, on tool-use workflows specifically, exceeds both.
Moonshot also offers Kimi Code, a terminal-based coding agent comparable to Claude Code, starting at $19 per month. Or you download the weights from Hugging Face and run everything locally, on your own infrastructure, with nothing leaving your servers. For any company handling sensitive client data, that last option eliminates the privacy question.
The Harvard Professor Who Studied This Exact Pattern for 30 Years
There is a researcher at Harvard Business School named Clayton Christensen who spent his entire career studying a single phenomenon: why do market leaders systematically get beaten by inferior products? His conclusion, published in The Innovator’s Dilemma, is that the inferior product is always cheaper, always more accessible, and improves faster than the market’s needs advance.
The PC against the mainframe.
The digital camera against Kodak.
Netflix against Blockbuster.
In every case, the incumbent had the objectively better product. In most cases, the incumbent lost. When you look at Kimi K2.7 Code next to Claude Opus 4.8 — the first is open source, five times cheaper to run, and the second is locked behind an export restriction — the Christensen pattern is recognizable enough to be uncomfortable.
The gap between open-source and closed-source models narrows with every release. K2.7 Code does not beat GPT-5.5 or Claude Opus 4.8 on raw coding benchmarks. But it beats them on the metric that matters most for autonomous agents, it costs a fraction of what they charge, and it runs on hardware you control. For the workflows that are growing fastest in the industry, that combination is hard to beat.
And the model was released thirteen days ago. The quantized versions that will make it runnable on consumer hardware are expected within weeks.
Thanks for reading. There have been five major releases in under a year. The pace is not slowing down. Follow me or subscribe for more AI analysis. Don’t forget to subscribe to my newsletter for early access or support me.