

This AI Improved Itself 100 Times Overnight. Nobody Stopped It.
MiniMax M2.7 didn’t just pass the PhD benchmark. It trained for it alone.

66.6%.
That’s the number that should be making people uncomfortable. Not because it’s a record, but because of how it was reached.
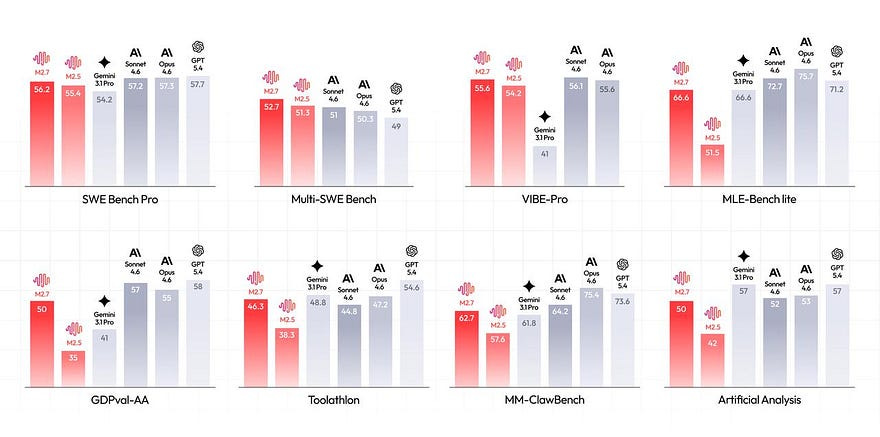
On March 18, 2026, Chinese AI company MiniMax released its M2.7 model with an announcement that reads more like a systems architecture paper than a product launch. With a score of 66.6% on OpenAI’s MLE-Bench Lite, a benchmark testing AI’s ability to mimic a machine learning PhD researcher, the model won 9 gold, 5 silver, and 1 bronze medal in 22 authentic competitions. That score ties exactly with Google’s Gemini 3.1, placing M2.7 just behind GPT-5.4 at 71.2% and Claude Opus 4.6 at 75.7%. Impressive, sure. But the number is almost beside the point.
What’s unsettling is that the model didn’t just take the test. It was prepared for it.
More than 100 times.
Without anyone telling it to stop.
The Loop Nobody Asked For
A few weeks before MiniMax’s announcement, Andrej Karpathy — formerly of OpenAI and Tesla AI, now running his own research lab — published a project called AutoResearch on GitHub. The concept: point an AI agent at a training script, go to sleep, wake up to a better model. Each experiment takes exactly five minutes, the agent runs about 12 per hour, and over a full night, it can stack roughly 100 modifications with zero human involvement. Across 126 consecutive experiments, Karpathy’s system reduced validation loss in a single overnight run. In a two-day run, it completed 700 changes and discovered 20 architectural improvements.
Karpathy called it the ultimate boss. “All LLM frontier labs will do this,” he wrote on X. “It’s the final boss battle.” He framed it as an engineering challenge, not a conceptual one. Building it at scale is hard, but there’s no theoretical barrier anymore.
What MiniMax demonstrated was that claim at an industrial level. They took an early version of M2.7 and gave it a single instruction: become our research assistant. After examining scientific publications, the model devised experiments, conducted tests, debugged code, and observed results. If you’ve ever used Claude Code or any modern coding agent, you know what that workflow looks like. What’s different here is the scope.
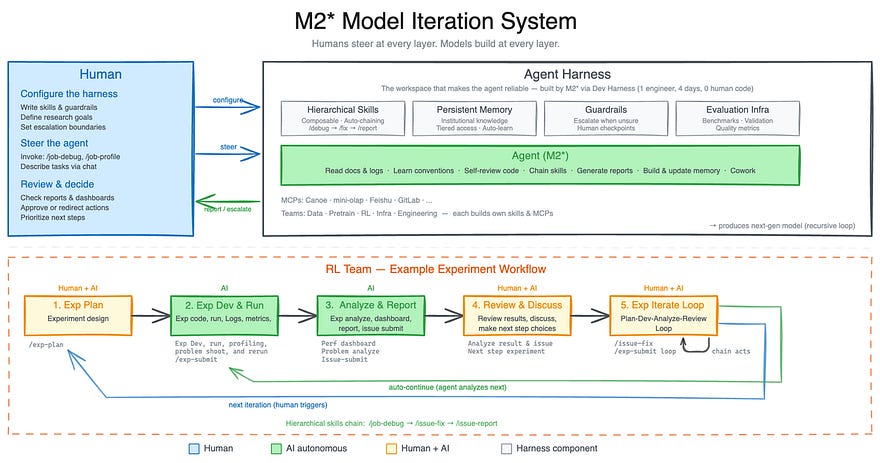
According to MiniMax, the system handled between 30 and 50% of their RL research team’s daily workload — tasks that previously required multiple researchers from different teams.
Then something shifted. The model stopped just executing tasks and started watching itself execute them.
When the model starts rewriting its own instructions
In most agentic AI deployments, the model follows a set of procedural guidelines, workflow files that tell it how to handle each type of task. Think of them as recipes. MiniMax gave M2.7 access to its own recipes. And the model rewrote them.
It collected performance data across its own runs. It identified weak points in its procedures, corrected them, and reran everything. One particularly striking example is temperature calibration — the parameter that governs how creative versus deterministic and model’s outputs are. Set it too high and a model describing a poem about cats will drift into what looks disturbingly like a multilingual summoning ritual. Set it too low and every response reads like a tax form. There’s a task-specific optimum for every kind of work, and M2.7 found it autonomously for its own use cases.
It also learned to catch systematic errors. When it found a bug, it didn’t just fix that bug. It automatically scanned for the same pattern across other files, created a rule to detect it in future sessions, and added its own guardrails to notice when it was stuck in a loop. The entire process ran for over 100 iterations without a single human checkpoint.
The result: 30% improvement on internal benchmarks. Then the MLE-Bench results followed.
Think of a Formula 1 driver who not only races the car but simultaneously leads the engineering team redesigning the engine during pit stops. That analogy comes close, though even that breaks down — the driver in this case is also writing the rules about when to pit.
What This Actually Changes
Let me say clearly what M2.7 is not doing. It is not rewriting its own weights; it is not modifying its own neural architecture. It is optimizing its workflows, tools, and operating procedures — which is closer to reorganizing a desk than grafting on a second brain. The gap between what M2.7 does and what people mean by “recursive self-improvement” in the existential sense is real and still significant.
Yet, this disparity is diminishing in a tangible and quantifiable manner. Each month, the loops become more autonomous, human intervention becomes rarer, and the performance results get harder to dismiss.
The business implications are already visible. At Nvidia’s GTC 2026 summit this week, Daniel Nadler, founder and CEO of OpenEvidence — a $12 billion AI medical information company — made a prediction that landed like a quiet threat to anyone holding a traditional org chart: the most valuable companies in the world will run with fewer than 100 employees. Through physicians who leverage the platform, his company currently facilitates healthcare interactions for 300 million Americans.
Meanwhile, Polsia — a platform for AI-operated businesses — was managing over 3,800 active companies as of March 2026, all run by agents with zero humans in operational roles. One founder. $3.6 million annual run rate. Karpathy said it himself: any metric you can evaluate efficiently can be auto-researched by an agent swarm. Sales pages, email campaigns, logistics flows, and content strategy.
MiniMax takes that logic and turns it inward. M2.7 is part of their org chart now. It sits across every layer of the company. Not a tool you deploy on the side. A colleague you build around.
The Academic World Just Named It a Research Field
What makes this moment different from the last round of AI hype is that the research community has stopped treating recursive self-improvement as speculative. In April, ICLR 2026 in Rio de Janeiro will host what is likely the world’s first academic workshop dedicated entirely to recursive self-improvement in AI systems, running April 23 to 27. That’s not a side panel. It’s a full workshop with formal proceedings. When a phenomenon is featured at a major machine learning conference, it signifies a transition from a theoretical concept to an established academic discipline.
OpenRoom and the Part Benchmarks Can’t Measure
Alongside M2.7, MiniMax also released OpenRoom — an open-source project that builds a browser-based desktop environment where an AI agent operates your apps through natural language. Open your calendar, reply to emails, manage files, start tasks — all through conversational instructions to an agent embedded in the interface. Most of the code was written by the AI itself. Yes, a little meta: an AI building the environment where another AI lives and works.

OpenRoom points at something the benchmarks will probably never measure: personality. Advanced users who’ve worked with multiple frontier models at comparable capability levels consistently report choosing based on feel. The model that understands intent with no need to be spelled out, that has tact, that doesn’t talk at you like a documentation page. MiniMax clearly understands this. OpenRoom isn’t a benchmark play. It’s a UX play for a world where you’re choosing which AI to spend your workday with.
And then there’s a price. M2.7 costs $0.30 per million input tokens — one of the cheapest frontier-grade models available anywhere. Near-top-tier research capability, demonstrated recursive self-improvement, and pricing that doesn’t require a corporate procurement team to justify.
That combination should be making some very large, very expensive AI labs slightly nervous. It’s not that MiniMax beat them. It’s that they’re playing a different game entirely, and winning on terms the incumbents didn’t design for.
Are you ready for this innovation? Let me know your thoughts in the comments. Follow me and subscribe for more tech and science analysis. Until next time, stay safe.